What is Gradient Descent ?
Gradient Descent is a machine learning algorithm which operates iteratively to find the optimal values for it’s parameters. It takes into account, user defined learning rate and initial parameter values.
Working : (Iterative)
(1) Start with initial values.
(2) Calculate cost.
(3) Update values using update function.
(4) Returns minimized cost for our cost function
Why do we need it ?
Generally, what we do is, we find the formula that gives us the optimal values for our parameter. But in this algorithm it finds the value by it self! Interesting, isn’t it?
Let’s have a look at various examples to understand it better.
Gradient Descent Minimization — Single Variable :
We’re going to be using gradient descent to find θ that minimizes the cost. But let’s forget the Mean Squared Error (MSE) cost function for a moment and take a look at gradient descent function in general.
Now what we generally do is, find the best value of our parameters using some sort of simplification and make a function that will give us minimized cost. But here what we’ll do is take some default or random for our parameters and let the our program run iteratively to find the minimized cost.
General Idea (without gradient descent):
Derivation of Linear Regression
Still confused?
Let’s take a very simple function to begin with: J(θ) = θ² , and our goal is to find the value of θ which minimizes J(θ).
From our cost function we can clearly say that it will be minimum for θ= 0,but it won’t be so easy to derive such conclusions while working with some complex functions.
(1) Cost function : We’ll try to minimize the value of this function.
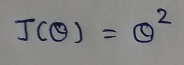
(2) Goal : To minimize the cost function:

(3) Update Function : Initially we take random number for our parameters, which are not optimal. To make it optimal we have to update it at each iteration. This function takes care of it.
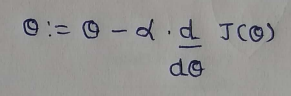
(4) Learning rate : The descent speed.
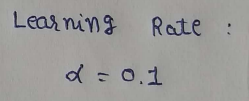
(5) Updating Parameters :
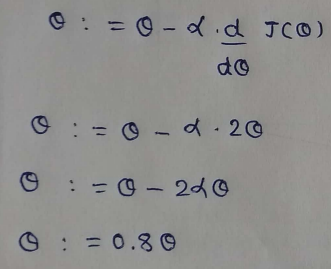
(6) Table Generation :
Here we are stating with θ = 5.
keep in mind that here θ = 0.8*θ, for our learning rate and cost function.
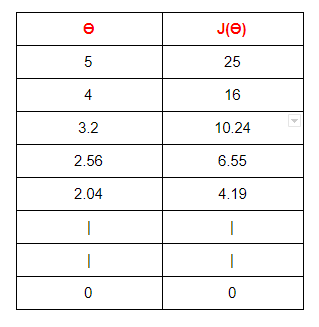
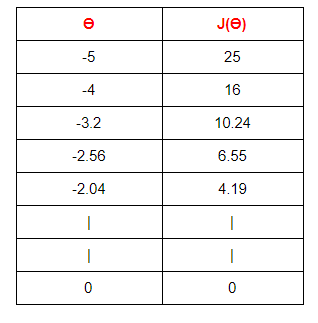
Here we can see that as our θ is decreasing the cost value is also decreasing. We just have to find the optimal value for it. To find the optimal value we have to do perform many iterations. The more the iterations, the more optimal value we get!
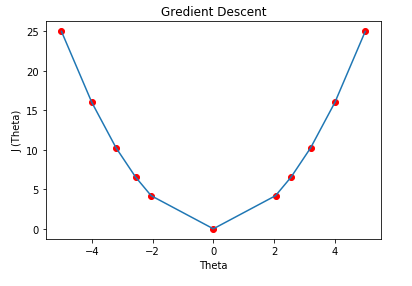
(7) Graph : We can plot the graph of the above points .
Cost Function Derivative :
Why does the gradient descent use the derivative of the cost function? We want our cost function to be minimum, right? Minimizing the cost function simply gives us the lower error rate in predicting values. Ideally we take the derivative of a function to 0 and find the parameters. Here we do the same thing but we start from a random number and try to minimize it iteratively.
The learning rate / ALPHA :
The learning rate gives us solid control over how large of steps we make. Selecting the right learning rate is very critical task. If the learning rate is too high then you might overstep the minimum and diverge. For example, in the above example if we take alpha =2 then each iteration will take us away from minimum. So we use small alpha value. But the only concern with using small learning rate is we have to perform more iteration to reach the minimum cost value, this increase training time.
Convergence / Stopping gradient descent :
Note that in the above example the gradient descent will never actually converge to minimum of theta= 0. Methods for deciding when to stop our iterations are beyond my level of expertise. But i can tell you that while doing assignments we can take a fixed number of iterations like 100 or 1000.
Gradient Descent : Multiple Variable :
Our ultimate goal is to find the parameters for MSE function, which includes multiple variables. So here we will discuss a cost function which as 2 variables. Understanding this will help us very much in our MSE Cost function.
Let’s take this function :
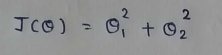
When there are multiple variables in the minimization objective, we have to define separate rules for update function. With more than one parameters in our cost function we have to use partial derivative. Here I simplified the partial derivative process. Let’s have a look at this.
(1) Cost Function :

(2) Goal :

(3) Update Rules:
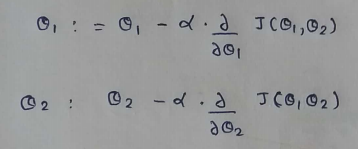
(4) Derivatives :
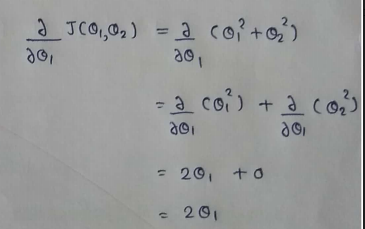
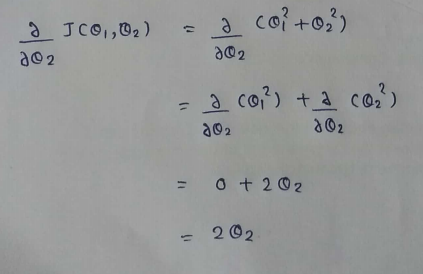
(5) Update Values :
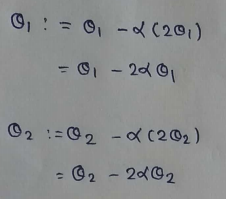
(6) Learning Rate:
(7) Table :
Starting with θ1 =1 ,θ2 =1. And then updating the value using update functions.
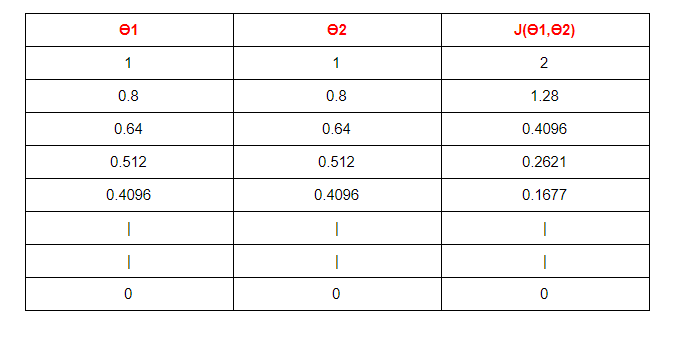
(8) Graph :
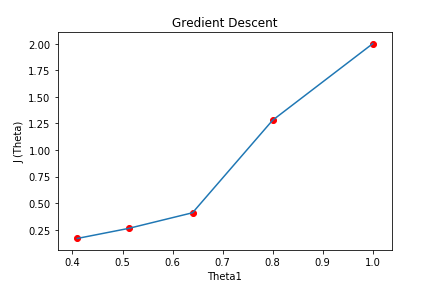
Here we can see that for as we increase our number of iterations, our cost value is going down.
Note that while implementing the program in python the new values must not be updated until we find new values for both θ1 and θ2. We clearly don’t want to use new value of θ1 to be used in old value of θ2.
Gradient Descent of MSE :
Now that we know how to perform gradient descent on an equation with multiple variables, we can return to looking at gradient descent on our MSE cost function.
Let’s get started..
(1) Hypothesis function :
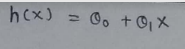
(2) Find the derivative :
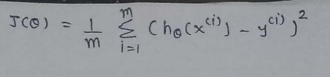
(3)Find partial derivative of J(θ0,θ1) w.r.t to θ1 :
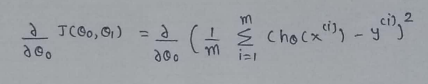
(4) Simplify a little :
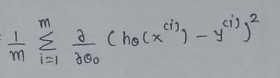
(5) Define a variable u :
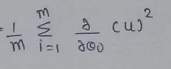
(6) Value of u:
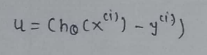
(7) Finding partial derivative :

(8) Rewriting the equations :
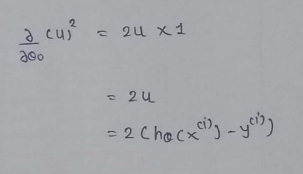
(9) Merge all the calculated data:
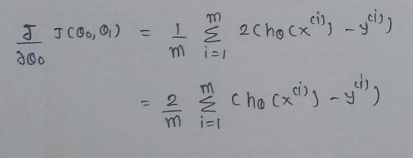
(10) Repeat the same process for derivation of J(θ0,θ1) w.r.t θ1 :



Some Basic Rules For Derivation:
(1) Scalar Multiple Rule :
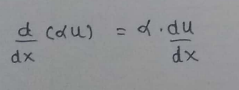
(2) Sum Rule :
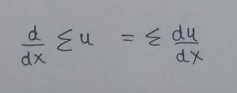
(3) Power Rule :
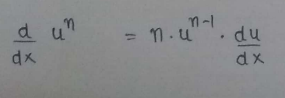
(4) Chain Rule:
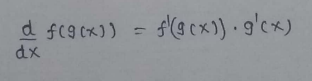
One Half Mean Squared Error :
We multiply our MSE cost function with 1/2, so that when we take the derivative the 2s cancel out. Multiplying the cost function by scalar does not affect the location of minimum, so we can get away with this.
Final :
(1) Cost Function : One Half Mean Squared Error :
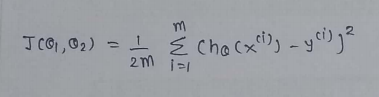
(2) Goal :

(3) Update Rule :

(4) Derivatives :
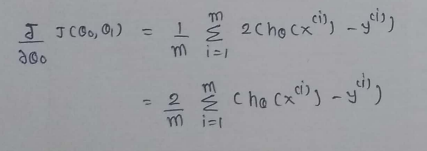
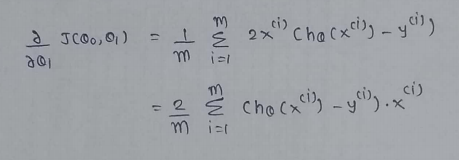
So, that’s it. We finally made it!
We can use the same method as mentioned above to find the optimal values for our parameters.
Moving Forward,
In the next article we’ll see about how we can implement this algorithm using python from scratch(without using any libraries!)
To find more such detailed explanation, visit my blog: patrickstar0110.blogspot.com
If you have any additional confusions, feel free to contact me. shuklapratik22@gmail.com
To learn some linear regression concepts :
Part 1 : Linear Regression From Scratch.
Part 2 : Linear Regression Line Through Brute Force.
Part 3 : Linear Regression Complete Derivation.
Part 4 : Simple Linear Regression Implementation From Scratch.
Part 5 : Simple Linear Regression Implementation Using Scikit-Learn.
 |
| Thank You! |
No comments:
Post a Comment